祝オープンソース化。
STF 分散オブジェクトストレージシステム
http://labs.edge.jp/stf/
ライブドアのサービスで主に画像管理用に使っているSTFがオープンソースで公開されています。
Perl/PSGI、Q4M、MySQL、Apacheという、Webアプリケーションエンジニアにとってとてもなじみやすい構成を取っており、実際運用もしやすくなっています。
ただひとつ気になるのはMySQLのデータのデカさ。3億オブジェクト/10億エンティティを保存した段階でのMySQLのデータサイズは、約220GBにもなります。これを潤沢にメモリを積み、SSDを4本RAID10にしたサーバにて運用しております。
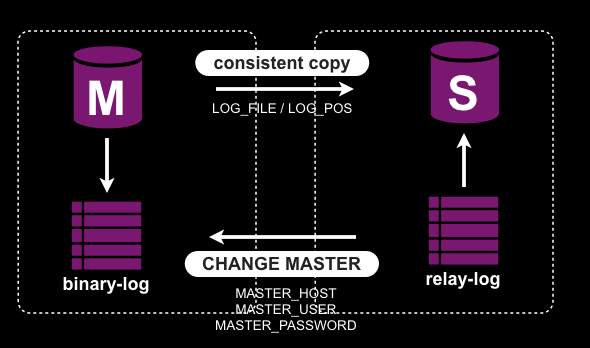
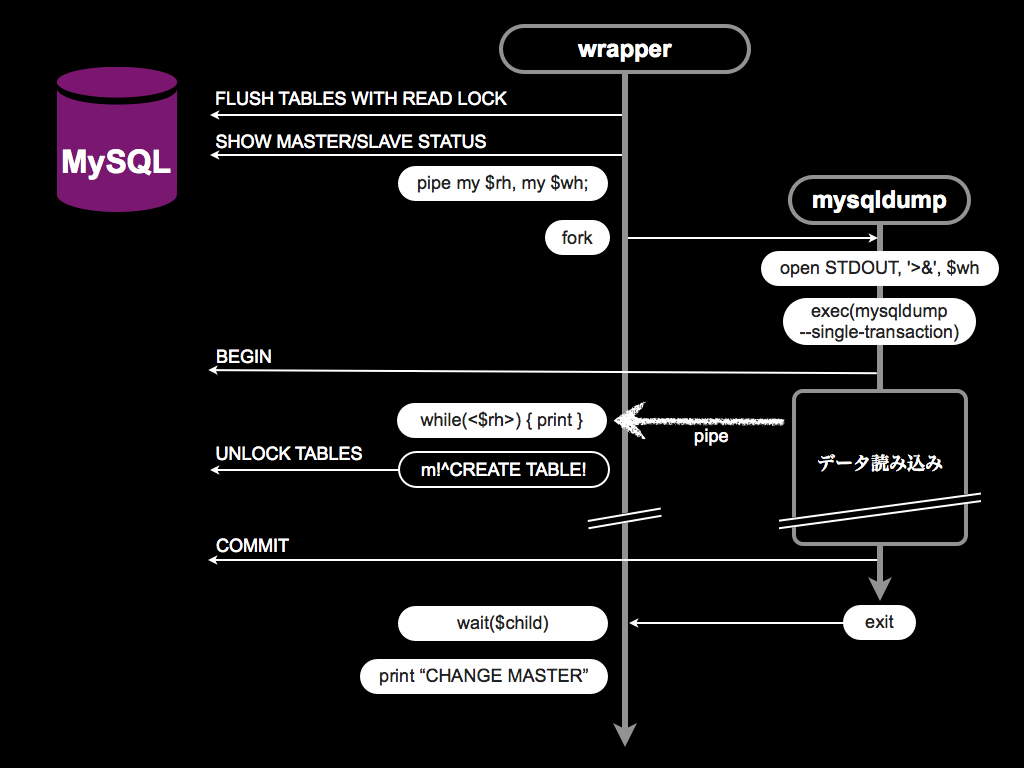
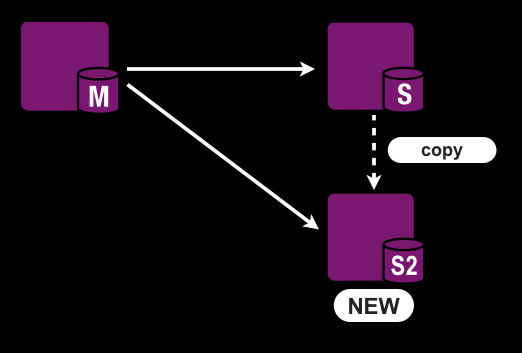
データの取り回しも大変で、データのダンプに数時間、リストアに数十時間、レプリケーションが追いつくのにまた数時間と移設作業を行うのにまるまる一週間かかるような感じです。とってもカジュアルではありませんね。
テーブル構成
STFの主なテーブルは以下の4つです。
- bucket
- object
- entity
- storage
bucketはオジェクトをまとめる単位。objectは外から見えるファイル、entityはファイルの実体でサーバに分散配置されます。そのサーバについて定義するのがstorageテーブルです。
すべてのスキーマはソースコードの中に含まれるので以下から取得可能です。
https://github.com/stf-storage/stf/blob/master/misc/stf.sql
このテーブルのうち、データサイズが大きくなるのはobjectとentityの2つ。
CREATE TABLE object (
id BIGINT NOT NULL PRIMARY KEY,
bucket_id BIGINT NOT NULL,
name VARCHAR(255) NOT NULL,
internal_name VARCHAR(128) NOT NULL,
size INT NOT NULL DEFAULT 0,
num_replica INT NOT NULL DEFAULT 1,
status TINYINT DEFAULT 1 NOT NULL,
created\_at INT NOT NULL,
updated\_at TIMESTAMP,
UNIQUE KEY(bucket_id, name),
UNIQUE KEY(internal_name)
) ENGINE=InnoDB;
CREATE TABLE entity (
object_id BIGINT NOT NULL,
storage_id INT NOT NULL,
status TINYINT DEFAULT 1 NOT NULL,
created_at INT NOT NULL,
updated_at TIMESTAMP,
PRIMARY KEY id (object_id, storage_id),
KEY(object_id, status),
KEY(storage_id),
FOREIGN KEY(storage_id) REFERENCES storage(id) ON DELETE RESTRICT
) ENGINE=InnoDB;
データサイズを小さく保つための工夫
まず object テーブルをみて気になるのが、ユニーク属性を保つインデックスが3つあるということ。
- PRIMARY KEY
- UNIQUE KEY(bucket_id, name)
- UNIQUE KEY(internal_name)
PRIMARY KEYはBIGINTで時間とDispatcherサーバに割り当てられたIDから計算されるユニークな数値です。2つは目システムの外から見えるバケットとファイル名のユニーク制限。そして3つ目がSTF内部でのファイル名です。
nameもinternal_nameもVARCHARとなるので、インデックスのサイズも大きくなりそうです。そこで利用できるのがMurmurHash等を使いより小さいデータにインデックスを張る方法。
データ分散とインデックス最適化のためのハッシュ関数の利用 - Perl Advent Calendar Japan 2011 Hacker
Track
http://perl-users.jp/articles/advent-calendar/2011/hacker/11
MurmurHashは32bitの数値となるのでハッシュ値が衝突する可能性が割と高いと思われるので、実際に使う場合はhash値をにユニークインデックスを張らず、通常のインデックスとし、データ追加時にトランザクションを使ってデータが被らないようにする必要があります。
internal_nameについては、本当にこの値が必要かどうか考えることが必要そうです。ここまで既にテーブル上に2つのユニークな値があるので、そっちを活用すればインデックスだけではなくカラム自体の削除もできそうです。例えば、PRIMARY KEYのBIGINTを内部のファイル名にしても良いはずです。
entityテーブルについては、2点ほど気になる点があります。1つはcreated_atとupdated_atのカラム、もう一つがKEY(object_id, status)のインデックスです。
MySQLのドキュメントに各データタイプにおける必要保存領域が書かれています。
10.5. データタイプが必要とする記憶容量
http://dev.mysql.com/doc/refman/5.1/ja/storage-requirements.html
created_atとupdated_atはそれぞれINTとTIMESTAMPなので、4byte+4byte=8byte必要となります。10億レコードあれば8GB分のデータにもなります。消すと若干節約できますね。
KEY(object_id, status)のインデックスも基本必要ないはずです。object_idを指定した段階で結果はオブジェクトの複製数(せいぜい3から5)にしぼらるので、statusをインデックスに含めなくても高速に検索可能です。PRIMARY KEYが(object_id, storage_id)なのでこちらで十分に事足ります。
ここまでぐだぐだと書いた内容を入れ込むとスキーマはこんな感じかな
CREATE TABLE object (
id BIGINT NOT NULL PRIMARY KEY,
bucket_id BIGINT NOT NULL,
name VARCHAR(255) NOT NULL,
name_hash INT UNSIGNED NOT NULL,
size INT NOT NULL DEFAULT 0,
num_replica INT NOT NULL DEFAULT 1,
status TINYINT DEFAULT 1 NOT NULL,
created_at INT NOT NULL,
updated_at TIMESTAMP,
KEY(bucket_id, name_hash)
) ENGINE=InnoDB;
CREATE TABLE entity (
object_id BIGINT NOT NULL,
storage_id INT NOT NULL,
status TINYINT DEFAULT 1 NOT NULL,
PRIMARY KEY id (object_id, storage_id),
KEY(storage_id),
FOREIGN KEY(storage_id) REFERENCES storage(id) ON DELETE RESTRICT
) ENGINE=InnoDB;
データサイズがどれくらいになるかはやってみないとわからないけど、確実に小さくはなって、データのハンドリングが楽になると思うので、仕事が始まったらできるところからやってみたいです > 誰か