GreenBuckets という Object Storage を作りました
Object Storage とは何かというと、OSSではOpenStack Object StorageとかMogileFS 、Webサービスで使われているところでは mixi の ImageCluster とか livedoor の STF とか、比較にならないけどAmazon S3とかそういったたぐいのものです。しばしば画像のストレージなんかに使われていると思います。今回作ったのは GreenBuckets というもので、mixiのImageClusterの構成をまねしつつ、stfと同じようにバケット単位での操作を可能としています。なんですでにあるのに作ったのかというと、主に「つくってみかったから」ですね。一応目標として
- シンプルだけど使える
- cpanm でインストールが完了する
- できるだけ少ない依存関係
- 素のMySQLだけで動く
- mapping のDBのインデックスサイズをできるだけ小さく保つ
- 普通のサーバで数億ファイルまで管理可能を目標
- Storageは既存のHTTPdを利用する
- 運用のノウハウを生かす
あたりをあげました。現状動作実績なしなので注意。
ソースコード: https://github.com/kazeburo/GreenBuckets
そんな GreenBuckets の構成ですが
- Dispatcher
- JobQueue Worker
- DAV Storage
- MySQL
の4つになります。dispatcher と JobQueue Worker は Perlで構築され、それぞれデーモンとして動作します。DAV StorageはApache mod_dav や Nginx、Perlbal等の既成のHTTPdが利用できます。MySQLはmapping用のデータとJobQueueのQueue等を保存します。
それぞれの役割を図にすると以下のようになります。まず、画像を保存するときから
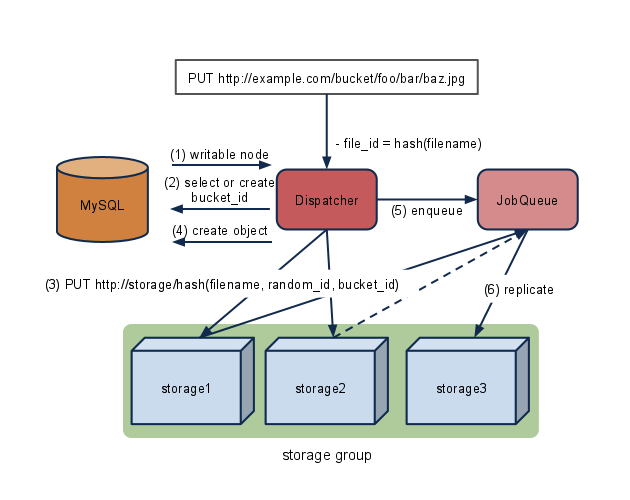
画像を保存するときには、dispatcherに対して、PUTもしくはPOSTでデータを送ります。PUTだと同じファイル名のファイルに対し上書きができ、POSTだと上書きせずにエラーになります。(1)dispatcher はまず保存ができるノード(DAV Storage)をMySQLに問い合わせます。ノードは決められたレプリカ数のあらかじめ決められた組で構成されています。レプリカ数は2以上で設定可能です。このあたりはmixiのストレージと同じです。 次に(2)URL からバケット名を抜き出し、バケットの有効性を確認します。もしバケットがなければ自動で作成されます。 (3) ノードが決まったら、DAVプロトコルを利用してPUTします。自動でディレクトリを作成したりしないので、Apacheのmod_davだと最初に必要分を作成しておいたほうがいいかもしれません。内部のPATHは
http://{node}/\d{2}/\d{2}/sha224_hex( filename + random_id + バケットID)
で構成されます。\d{2} は filename の murmur_hash 値の下4桁です。オブジェクトの保存時にはすべてのノードにコピーするのではなく、2ノードのみにコピーし、残りをキューに任せます(5)。
この2ノードの選択方法は、ノードのIDと内部のPATHのhash値によって決められています。オブジェクトによって一意に決まる順序となります
my @url = sort {
murmur_hash($a->{node_id} . $a->{path}) <=> murmur_hash($b->{node_id} . $b->{path})
} @...
オブジェクトの取得時もおなじルールを適用するので、キューによってコピーが遅延されたノードにデータを取りにいく可能性を小さくしています。また同じデータはかならず同じノードへアクセスするので、雀の涙ほどかもしれませんがディスクキャッシュの効率をあげることもできます。
(4) データのコピーが終わったら、MySQLにどのノードの組に格納したのかの情報を追加します。その際URLをキーにするのではなく、murmur_hash値を使います。
INSERT INTO objects (fid,bucket_id,rid,gid,filename)
VALUES( murmur_hash(filename), バケットID, random_id,ノードグループID , filename);
これはMySQL上のインデックスのサイズを小さく保つのが目的です。murmur_hash は 32bit の UNIT を返すので、DBもINT UNSIGNED(4byte)で済みます。indexはこの fid と bucket_id にのみ張ります。murmur_hash の値は衝突する可能性があるので、index は張りませんが、もとのファイル名も保存し、取得時はかならず確認します。
(5) (6) キューはデータが保存されたノードから一度ファイルを取得してコピーします。もしコピーに失敗したときは、別のノードグループに保存しなおし、MySQLをアップデートします。
次に取得時ですが
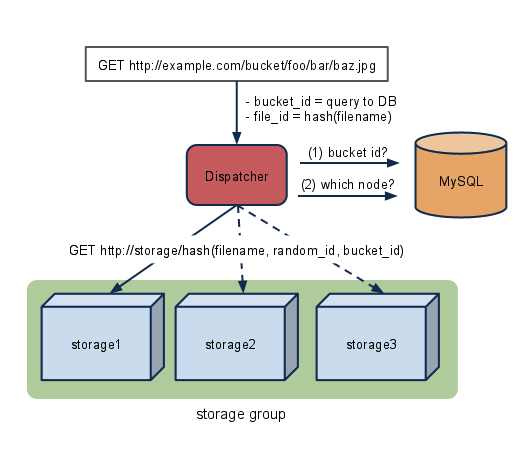
dispatcherに対して普通にGETリクエストを送ります。(1)まずPUT時と同じようにバケットを調べます。(2)次にファイル名からデータが保存されているノードを問い合わせます。この際PUT時と同じく、murmur_hashを使います。
SELECT filename,node_id,.. FROM objects WHERE bucket_id = バケットID AND fid = murmur_hash(ファイル名)
取得できたfilenameとリクエストされたファイル名が一致するか確認します。一致したらそのノードのIDと内部PATHで一意に決められた順序でストレージにアクセスし、コンテンツをクライアントに返します。
■使い方
今のところの使い方。そのうちCPANにあげれるようにしたいけど今のところgithubから。試すにはMySQLとPerlが必要です。
$ git clone git://github.com/kazeburo/GreenBuckets.git
$ cd GreenBuckets
$ perl Makefile.PL
$ cpanm --install-deps . # PerlbalとTest::mysqldとかが入るので注意
まず、MySQLにデータベースを作成
$ mysqladmin create greenbuckets
$ ./bin/greenbuckets scheme | mysql greenbuckets
「$ greenbuckets scheme」とすることでスキーマが出力されるのでそれをパイプで流します。
とりあえず、ストレージについてはPerlbalを使ってみます。それぞれのノードは
http://localhost:8080/1/
http://localhost:8080/2/
http://localhost:8080/3/
http://localhost:8080/4/
http://localhost:8080/5/
http://localhost:8080/6/
とトップディレクトリを変更することで代用します。1..3がグループ1、4..6がグループ2とします。これをDBに登録
INSERT INTO `nodes` VALUES (1,1,'http://127.0.0.1:8080/1/',1,1);
INSERT INTO `nodes` VALUES (2,1,'http://127.0.0.1:8080/2/',1,1);
INSERT INTO `nodes` VALUES (3,1,'http://127.0.0.1:8080/3/',1,1);
INSERT INTO `nodes` VALUES (4,2,'http://127.0.0.1:8080/4/',1,1);
INSERT INTO `nodes` VALUES (5,2,'http://127.0.0.1:8080/5/',1,1);
INSERT INTO `nodes` VALUES (6,2,'http://127.0.0.1:8080/6/',1,1);
INSERT INTO `nodes` VALUES (7,3,'http://127.0.0.1:8080/7/',1,1);
INSERT INTO `nodes` VALUES (8,3,'http://127.0.0.1:8080/8/',1,1);
INSERT INTO `nodes` VALUES (9,3,'http://127.0.0.1:8080/9/',1,1);
そして Perlbal を起動します。confは以下のような感じ
CREATE SERVICE static_server
SET role = web_server
SET listen = 0.0.0.0:8080
SET docroot = /tmp/greenbuckets
SET dirindexing = 1
SET enable_delete = 1
SET enable_put = 1
SET min_put_directory = 0
ENABLE static_server
put/deleteを有効にし、自動でディレクトリも作成するように設定します
$ perlbal -c etc/perlbal.conf
つぎに greenbucketsのconfigをします
$ ./bin/greenbuckets config > config.pl
これで設定ファイルのテンプレートが吐き出されるので、DBのユーザ名、パスワード等を変更します。変更したら dispatcher と jobqueue を起動します。
$ ./bin/greenbuckets dispatcher -c config.pl
$ ./bin/greenbuckets jobqueue -c config.pl
それぞれ起動していればインストール完了です。デフォルトdispatcherが5000番、jobqueueはステータス取得用のデーモンが5101番で起動します
curlを使ってPUTしてみます
$ curl -basic --user admin:admin -X PUT -d "Mary Poppins" \
http://localhost:5000/test/supercalifragilisticexpialidocious
OK
OKが返って来ました。実際保存されているか。確認します
$ find /tmp/greenbuckets -type f
/tmp/greenbuckets/1/88/85/d5e9c13ea8cc4fc218d54c6a3f55a663d52ea3f55f0d7c4ccca3e625
/tmp/greenbuckets/2/88/85/d5e9c13ea8cc4fc218d54c6a3f55a663d52ea3f55f0d7c4ccca3e625
/tmp/greenbuckets/3/88/85/d5e9c13ea8cc4fc218d54c6a3f55a663d52ea3f55f0d7c4ccca3e625
ノードグループ1の、ノード1、2、3に保存されているのが確認できました。次に実際に GET してみます
$ curl -v http://localhost:5000/test/supercalifragilisticexpialidocious
...
< HTTP/1.0 200 OK
< Date: Mon, 09 May 2011 14:49:53 GMT
< Server: Plack::Handler::Starlet
< Content-Type: text/plain
< Last-Modified: Mon, 09 May 2011 14:46:57 GMT
<
* Closing connection #0
Mary Poppins
ちゃんと保存したデータが得られました。ちゃんと動きそうです。ほっ。
今後の課題としては、CASをサポートしたいのと、遠隔地ノードを考えたいのと、実績と運用のドキュメントかな。もし社内外で興味のある方がいましたらご連絡ください。
