みなさん mysqldump は好きですか? 自分はどっちでもありません。
MySQLでよくあるMaster-Slave構成を作る手順は以下のようになると思います
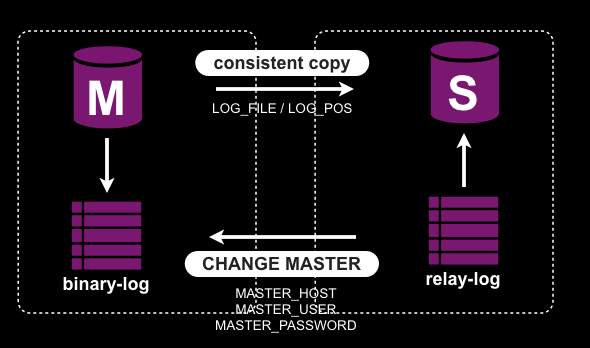
- MasterからSlaveとなるサーバに一貫性を保った状態のコピーをし、そのデータのバイナリログのファイル・ポジションをメモ。
- SLAVEでデータをリストアし、Masterのホスト名、レプリケーションに使うユーザ名・パスワードとメモしたバイナリログのポジションをCHANGE MASTER文に渡し、START SLAVE
一貫性の取れたコピーを作成するためにmysqldumpやxtrabackup、LVMなどでのスナップショットが利用できますが、もっとも簡単な方法がmysqldumpだと思います。
mysqldumpで一貫性のあるデータをとり、その際のバイナリログポジションを記録するには
$ mysqldump --single-transaction --master-data
とします。single-transactionでバックアップをトランザクション中で行い、—master-data=2 でバイナリログのポジションをバックアップの先頭にコメントとして記録できます。(single-transactionでもInnoDB以外のテーブルがある場合は一貫性のあるデータがとれない可能性があります)
実際のmysqldumpが発行しているクエリは以下のようになってます。
FLUSH LOCAL TABLES
FLUSH TABLES WITH READ LOCK
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ
START TRANSACTION WITH CONSISTENT SNAPSHOT
SHOW MASTER STATUS
UNLOCK TABLES
DB選択
テーブルからデータの読み込み
(@tmtms のメモより)
まずREAD LOCKをかけ、つぎにトランザクション開始し、バイナリログのポジションを確保。その後READ LOCKを解放し、(トランザクションはそのまま)データのダンプを行っています。
このようにmysqldumpで一貫性のあるデータコピーとバイナリログの位置を取得できます。
が
がががが、まぁよくある話で、MySQL 4.0のサーバに対して mysqldumpを実行すると
FLUSH TABLES WITH READ LOCK
BEGIN
DB選択
テーブルからデータの読み込み
COMMIT;
SHOW MASTER STATUS
UNLOCK TABLES;
と、なり、なんと最初から最後までREAD LOCKされ、dumpが終了するまでデータを更新できなくなってしまいます。数十GBになるデータを扱っている場合これでは運用が難しい。。。
Wrapper スクリプトの動作
そこで考えたのが2つのプロセスを組み合わせて、READ LOCKとトランザクションを発行する次の仕組み。
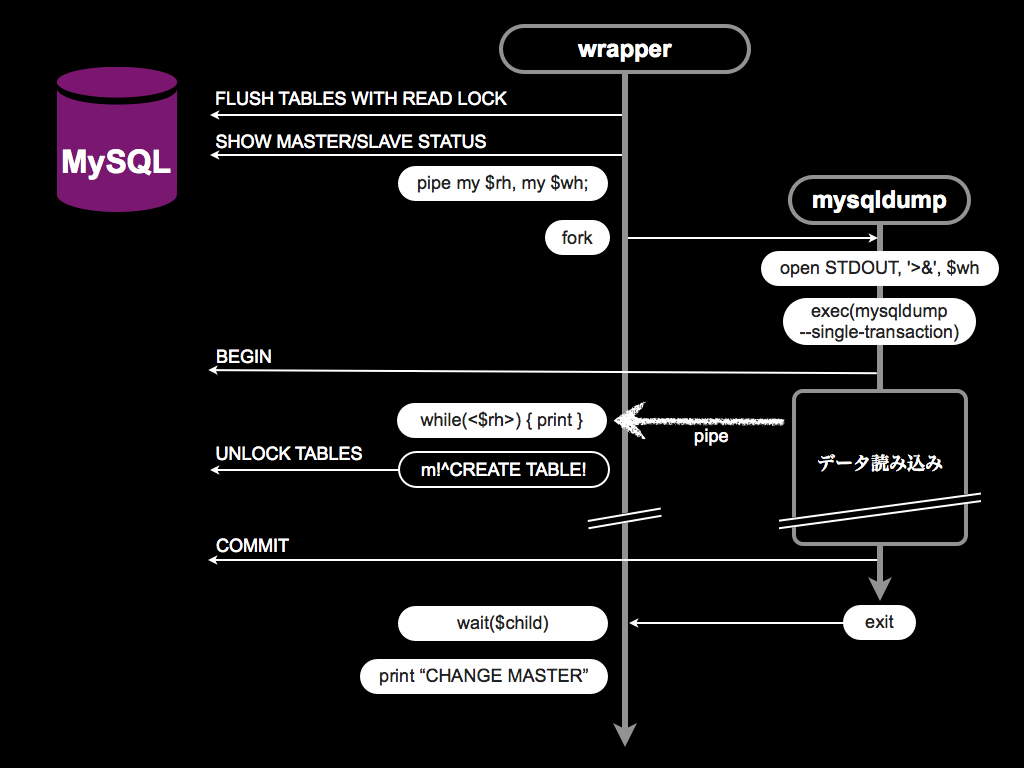
mysqldumpをラップするperlスクリプトを起動すると、まずMySQLに対してREAD LOCKを行い全ての更新を止めます。そしてバイナリログの情報を取得。
次に、pipeを作成し、fork。forkした子プロセスでは標準出力をpipeに結びつけ、mysqldumpをsingle-transactionオプション付きでexec。single-transactionが有効なのでmysqldumpはトランザクションを開始してデータコピーを開始します。そのデータはpipeを通して親プロセスに送られます。
親プロセスでは、pipeからデータを読み込み、そのまま標準出力します。その際最初のCREATE TABLEを見つけたら、最初に行ったREAD LOCKを解放し、そのあとは mysqldumpが終了するまで動き続けます。
実際に最初のREAD LOCKからダンプを開始し、LOCKが解放されるまでは1秒も掛からないのでほぼ無停止だと言えるでしょう。これでMySQL 4.0でも一貫性のとれたデータダンプと、バイナリログのポジション取得が可能となります。
この仕組みを実装したのが mysql40dump というスクリプトで、既に実際にサービスのデータベースの複製・バックアップに使っています。次に紹介する機能が便利なので、4.0だけではなくMySQL 5.1系でも動作確認しています。
mysql40dump の追加機能
まず1つ目がSHOW MASTER STATUSの代わりにSLAVE STATUSを実行する機能。
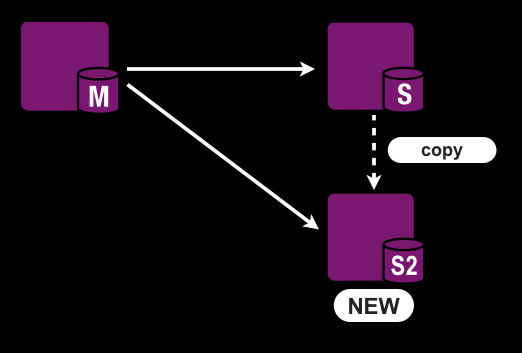
のようにSLAVEからSLAVEを作るときに使えます。MySQL 5.5から実装された mysqldump —dump-slave 相当の機能ですね。
もう一つが自身のIPアドレスを調べ自動でCHANGE MASTER文を構築する機能と、START SLAVEまで実行する機能。これでほぼ面倒なことなくレプリケーションの開始まで自動化ができるようになりました。この自動化のおかげて3つ4つ同時に異なるデータベースのコピーを行っていても全く苦にならず捗ります。
あと、MySQL 4.0でのバッドノウハウとしてダンプデータの先頭に
set FOREIGN_KEY_CHECKS=0
をいれます。これで何度泣いた事か。。
使い方
perlのスクリプトなのでインストールはcpanmでできます
$ cpanm https://github.com/downloads/kazeburo/mysql40dump/mysql40dump-0.03.tar.gz
$ mysql40dump -h
Master-Slave構成を取る場合
Masterにて
$ mysql40dump --master --repl --master-user user --master-password pass | gzip > dump.sql.gz
ファイルをコピーして Slaveにて
$ zcat dump.sql.gz | mysql
これでリストア後、レプリケーションの開始までやってくれます
Slaveを追加する場合
既存Slaveにて
$ mysql40dump --slave --repl --master-password pass | gzip > dump.sql.gz
ファイルをコピーして 新しいSlaveにて
$ zcat dump.sql.gz | mysql
これでMasterからのレプリケーションが開始されます。
簡単ですね!
次の課題はxtrabackupのwrapperかな
合わせて読みたい
図中のアイコンは、AWS Simple Icons for Architecture Diagrams を使いました
