Webアプリケーション内で処理を直列に実行せずにJob Queueに回して非同期に実行することが多くなって来て久しいと思いますが、そのおすすめ構成と気をつけることについてつらつらと。
1) 既存のデータベースをキューとして使う構成例
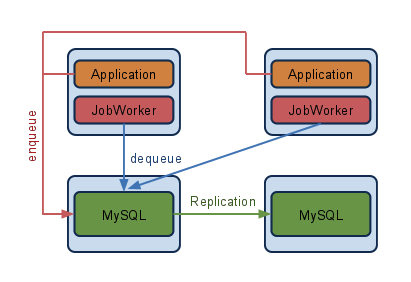
1つ目はMySQLなどのデータベースをキューとして用いる例。既にアプリケーションで利用しているデータベースにキュー用のテーブルを作成して利用します。データベースを利用したキュー管理の仕組みとしてJonk、Qudo、TheSchwartzなどがPerlでは有名どころです。 依存するミドルウェアが増えないので最もシンプルな構成になると思います。
上記の図ではWorkerはアプリケーション内で実行することで冗長性を確保しますが、キューを格納するデータベースはSPOFになります。しかし、、データベースに障害があった場合キューだけでなくすべてのサービスが停止すると思われますので、取り上げて問題となることはないでしょう。
性能についてですが、Workerがキューを取得する間隔がどうしても1秒やそれ以上になるので、キューを登録してから実行されるまでのレイテンシが大きく、負荷が大きくなるとキューが滞留してしまうことがあるかもしれません。新規にサービスを開始する際はまず依存が少ないこの構成をとって、キューの数を監視しつつ次のアクションを考えるのがおすすめです
2) 専用のメッセージキューを導入する構成例
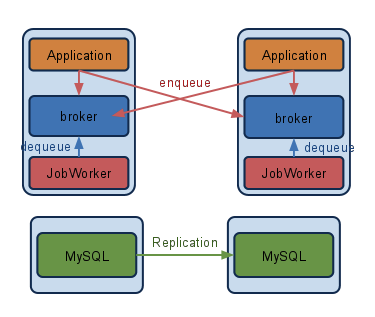
2つ目は専用のメッセージキューのミドルウェア(Message Broker)を導入する例になります。よく使われるソフトウェアはActiveMQやRabbitMQ、Q4Mあたりでしょうか。新たなミドルウェアを導入する分、システムが複雑になります。
冗長性を確保するため、これらのミドルウェアは2カ所以上で起動しキューは分散して登録します。分散にあたっては単にランダムやランドロビンでサーバを選ぶのではなく、特定のキー(例えばuser_id)に因ってサーバが一意に決まる剰余による分散やConsistent-Hashingを使うと、問題が起きたときにどのサーバがキューを処理したのか追いやすくなります。Workerの作り方に因ってはキューの処理する順も制御できるかもしれません。このためWorkerはlocalhostのメッセージキューだけを参照します。
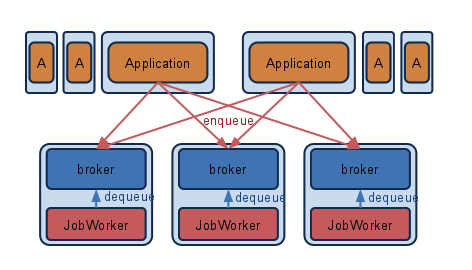
サービスが大きくなり、キューが捌けないようになった際には上の図のようにメッセージキューとWorkerをセットにしてサーバを増やしていきます。キューを登録する側にて追加したサーバを使うよう設定をするだけでサーバを増やして行くことができるので運用もわかりやすくなります。
3) Workerを作る際に気をつけること
キューを処理するWorkerはPreforkモデルで作成することをお勧めします。サーバがマルチコアになっているのにアプリケーションがシングルプロセスではあまり意味がありませんし、1プロセスで動作していて、キューの処理に時間が掛かると残りのすべてのキューが遅延してしまいます。この上でSignalをハンドリングして、Workerのgraceful shutdownができるようにしましょう。安全にアプリケーションのアップデートや設定変更を行うのに必須です。PerlではParallel::Preforkを使うと、PreforkしつつSignalを受けWorkerを再起動するデーモンが書きやすくなります。
また、ApacheのMaxRequestPerChildのような、一定数のキューを処理したら子プロセスが終了する仕組みが入っているとメモリを多く確保した場合でも、しばらくすれば解放されるので安心です。
Workerではデータベースへのコネクションなどのリソース管理も重要です。Workerプロセスが長い時間データベースへの接続を維持してしまうことで、データベースの最大接続数を使いきってしまったりリソースを無駄に使ってしまうこともあるので、注意が必要です。「1つのキューを処理 = Webサーバへの1リクエストに対する処理」のように捉えて制御することが重要です。
あ、あとログはちゃんと吐かないとsfujiwaraさんが○○にきます
