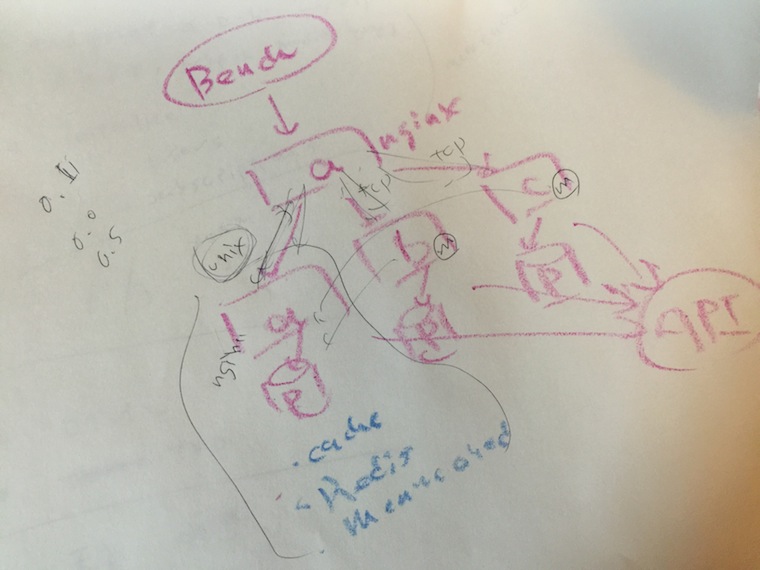
wrkに無理矢理なpatchをあてて、unix domain
socket経由でHTTPサーバをベンチマークできるようにしてみました。
pullreqはしてない。
GazelleやRhebokといったアプリケーションサーバを作っていますが、TCP経由のベンチマークではEphemeral Portの枯渇やTIME
WAITの上限にあたってしまい、ベンチマークがしづらいという問題があります。
そこでnginxをreverse proxyとして設置し、nginxとアプリケーションサーバ間をunix domain
socketで繋いでベンチマークをとっていましたが、nginxがボトルネックになりやすく、直接アクセスしたいなと考えていたので、やってみました。
これを使ってRhebokとUnicornの “Hello World” ベンチマークを行ったところ、unix domain
socketのベンチマーク結果はTCPに比べて、Rhebokで5倍、Unicornで3倍高速という数字がでました。

Rhebokは最新版でHTTP/1.1のサーバとなり、デフォルトでTransfer-Encoding: chunkedを使います。Unicornはchunked
transferを行わないので、機能的にあわせるためrack middlewareを導入しているのが上記のグラフの「Unicorn +
Chunked」です。
このベンチマーク結果をみると、やはりTCPの新規コネクションのコストは大きく、TCPの都度接続は避け、できるだけコネクションを使い回すか、unix
domain socketの使用したいと思うでしょう。
ただ、Reverse
Proxyとアプリケーションサーバ、もしくはクライアントとアプリケーションサーバ間のTCP接続をkeepaliveする場合、保持すべき接続数のチューニングが難しくなりがちなので、自分としてはお勧めしません。クライアントとのTCP接続の維持をReverse
Proxyで行い、アプリケーションサーバ間との接続はunix domain
socketを使うのがよいのでしょう。もちろん、両者が同じホスト上で動作していないと使えませんが。。
使い方
まずブランチ指定してcloneしてきて、make
$ git clone -b unixdomain https://github.com/kazeburo/wrk.git
$ cd wrk
$ make
-P オプションでパスを指定します。
$ ./wrk -t 1 -c 30 -d 30 -P /tmp/app.sock http://localhost/benchmark
簡単ですね
RhebokとUnicornのベンチマーク
ベンチマークはEC2のc3.4xlargeを使いました。コア数は16です。OSはAmazon Linuxです。
以下のカーネルチューニングをしました
$ sudo sysctl -w net.core.netdev_max_backlog=8192
$ sudo sysctl -w net.core.somaxconn=32768
$ sudo sysctl -w net.ipv4.tcp_tw_recycle=1
一番下はTCPのポート枯渇対策です。ただTCPのベンチマークはどれもtimeoutのエラーが出てしまっています。
Rubyはxbuildを使って2.1.0をインストール
$git clone https://github.com/tagomoris/xbuild.git
$ ./xbuild/ruby-install 2.1.5 ~/local/ruby-2.1
$ export PATH=/home/ec2-user/local/ruby-2.1/bin:$PATH
$ gem install rhebok unicorn
アプリケーションサーバのワーカー数は8とし、wrkはスレッド6個、同時接続数600で実行しました。
アプリケーションはconfig.ruに直接書いている
$ cat config.ru
class HelloApp
def call(env)
[
200,
{},
["hello world\n"]
]
end
end
run HelloApp.new
# run Rack::Chunked.new(HelloApp.new)
unicornの設定はこちら
$ cat unicorn.rb
worker_processes 8
preload_app true
#listen "/dev/shm/app.sock", :backlog=>16384
listen 8080, :backlog=>36384
Rhebok + unix domain socket
$ rackup -s Rhebok -O Path=/dev/shm/app.sock -O BackLog=16384 -E production -O MaxRequestPerChild=0 -O MaxWorkers=8 config.ru
$ ./wrk -t 6 -c 600 -d 30 --timeout 60 -P /dev/shm/app.sock http://localhost:8080/
Running 30s test @ http://localhost:8080/
6 threads and 600 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.73ms 244.96us 6.62ms 81.28%
Req/Sec 57.64k 4.04k 66.56k 69.06%
9762337 requests in 30.00s, 1.28GB read
Requests/sec: 325426.21
Transfer/sec: 43.76MB
Rhebok + TCP
$ rackup -s Rhebok -O Port=8080 -O BackLog=16384 -E production -O MaxRequestPerChild=0 -O MaxWorkers=8 config.ru
$ ./wrk -t 6 -c 600 -d 30 --timeout 60 http://localhost:8080/
Running 30s test @ http://localhost:8080/
6 threads and 600 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 36.02ms 194.43ms 1.83s 97.66%
Req/Sec 11.87k 2.20k 21.89k 89.91%
2021671 requests in 30.00s, 271.85MB read
Socket errors: connect 0, read 0, write 0, timeout 56
Requests/sec: 67392.13
Transfer/sec: 9.06MB
Unicorn + unix domain socket
$ unicorn -c unicorn.rb -E production config.ru TCP
$ ./wrk -t 6 -c 600 -d 30 --timeout 60 -P /dev/shm/app.sock http://localhost:8080/
Running 30s test @ http://localhost:8080/
6 threads and 600 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 3.21ms 170.17us 11.49ms 88.06%
Req/Sec 32.71k 2.04k 43.67k 65.95%
5534941 requests in 30.00s, 543.69MB read
Requests/sec: 184506.07
Transfer/sec: 18.12MB
Unicorn + TCP
$ unicorn -c unicorn.rb -E production config.ru TCP
$ ./wrk -t 6 -c 600 -d 30 --timeout 60 http://localhost:8080/
Running 30s test @ http://localhost:8080/
6 threads and 600 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 33.58ms 179.94ms 1.75s 97.80%
Req/Sec 11.01k 2.04k 22.00k 89.73%
1873600 requests in 30.00s, 184.04MB read
Socket errors: connect 0, read 0, write 0, timeout 49
Requests/sec: 62455.78
Transfer/sec: 6.13MB
Unicorn + chunked + unix domain socket
$ unicorn -c unicorn.rb -E production chunked.ru unix
$ ./wrk -t 6 -c 600 -d 30 --timeout 60 -P /dev/shm/app.sock http://localhost:8080/
Running 30s test @ http://localhost:8080/
6 threads and 600 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 5.24ms 265.60us 13.67ms 77.33%
Req/Sec 19.76k 1.79k 26.00k 68.71%
3404283 requests in 30.00s, 457.77MB read
Requests/sec: 113481.40
Transfer/sec: 15.26MB
Unicorn + chunked + TCP
$ unicorn -c unicorn.rb -E production chunked.ru tcp
$ ./wrk -t 6 -c 600 -d 30 --timeout 60 http://localhost:8080/
Running 30s test @ http://localhost:8080/
6 threads and 600 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 555.60ms 1.10s 3.43s 81.56%
Req/Sec 7.85k 5.05k 26.89k 65.28%
1339932 requests in 30.00s, 180.18MB read
Socket errors: connect 0, read 0, write 0, timeout 29
Requests/sec: 44659.91
Transfer/sec: 6.01MB
HTTP/1.1に対応したRhebok、Gazelleと共にお試しくださいませ。