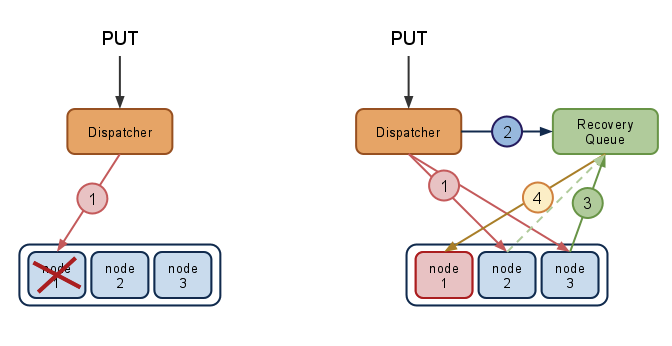
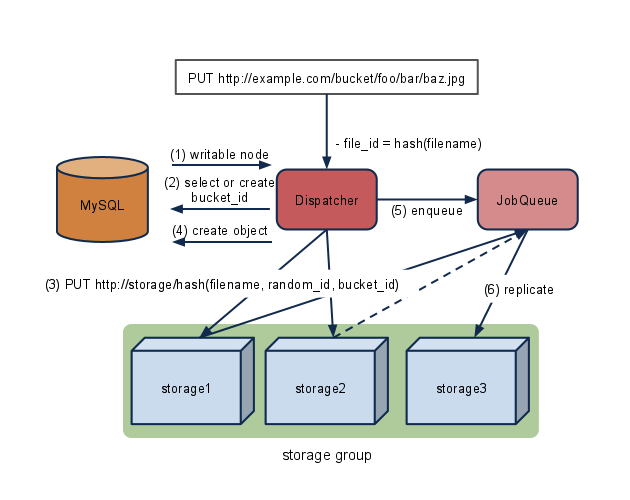
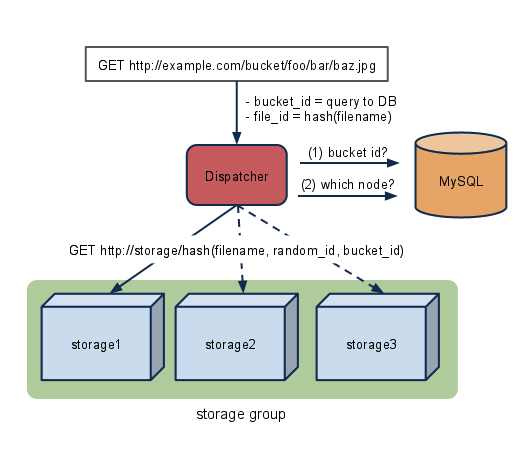
分散Object Storageの GreenBuckets ではストレージノードの実装を問わないので、こういうこともできると言う例
Kyoto Cabinet の Directry Hash DataBase を使うと、ファイルシステム上の1ファイルが1レコードとなるデータベースを作成することができます。通常のDBMでは数KBまでの小さいデータに性能が最適化されているのに対して、Directry Hash DataBaseでは数十KB〜のデータを扱いやすくなるということらしいです。
もちろん、Kyoto Tycoon からも使うことができるので、GreenBucketsのストレージノードとしても利用できます。
まず、ktserver でノードを立ち上げます。今回は試しに1つのktserverで複数のデータベースを担当させ、それぞれ1ノードとして扱います。
$ ktserver -li -port 8080 a.kcd b.kcd c.kcd
2011-05-29T00:42:04.418287+09:00: [SYSTEM]: ================ [START]: pid=77706
2011-05-29T00:42:04.424942+09:00: [SYSTEM]: opening a database: path=a.kcd
2011-05-29T00:42:04.426206+09:00: [SYSTEM]: opening a database: path=b.kcd
2011-05-29T00:42:04.427222+09:00: [SYSTEM]: opening a database: path=c.kcd
2011-05-29T00:42:04.428189+09:00: [SYSTEM]: starting the server: expr=:8080
2011-05-29T00:42:04.428292+09:00: [SYSTEM]: server socket opened: expr=:8080 timeout=30.0
2011-05-29T00:42:04.428329+09:00: [SYSTEM]: listening server socket started: fd=9
a.kcd、b.kcd、c.kcd というデータベースが作成されました。これをノードとしてGreenBucketsに登録します
mysql> select * from nodes;
+----+-----+-----------------------------+--------+-------+--------+
| id | gid | node | online | fresh | remote |
+----+-----+-----------------------------+--------+-------+--------+
| 1 | 1 | http://127.0.0.1:8080/a.kcd | 1 | 1 | 0 |
| 2 | 1 | http://127.0.0.1:8080/b.kcd | 1 | 1 | 0 |
| 3 | 1 | http://127.0.0.1:8080/c.kcd | 1 | 1 | 0 |
+----+-----+-----------------------------+--------+-------+--------+
わかりやすいですね。
Kyoto Tycoon では最初のディレクトリをデータベース名として扱うので、GreenBucketsのほうからディレクトリを含まないURIでノードにアクセスする必要があります。そのためには、GreenBucketsのconfigで
flat_dav => 1,
を指定してください。上の例のように既にデータベース名がノードに含まれている場合はこの必要はありません。
これで、GreenBucketsを起動して、
$ PLACK_ENV=development ./bin/greenbuckets jobqueue -c etc/config.pl
$ PLACK_ENV=development ./bin/greenbuckets dispatcher -c etc/config.pl
curlでアクセスしてみます。
$ curl -v -basic --user admin:admin -X PUT -d 'IloveKyoto' http://localhost:5000/test/test
* HTTP 1.0, assume close after body
< HTTP/1.0 200 OK
< Date: Sat, 28 May 2011 15:50:24 GMT
< Server: Plack::Handler::Starlet
< Content-Type: text/html; charset=UTF-8
<
* Closing connection #0
OK
OKが返って来て、オブジェクトが保存されました。
この時のKyoto Tycoon側のログをみると、
2011-05-29T00:50:24: [INFO]: connected: expr=127.0.0.1:60567
2011-05-29T00:50:24: [INFO]: (127.0.0.1:60567): PUT /c.kcd/59/47/04b09ad074b6c9c58132c3dbfd81879f6294efbe9f1381ae295cf2ac HTTP/1.1: 201
2011-05-29T00:50:24: [INFO]: (127.0.0.1:60567): PUT /b.kcd/59/47/04b09ad074b6c9c58132c3dbfd81879f6294efbe9f1381ae295cf2ac HTTP/1.1: 201
2011-05-29T00:50:24: [INFO]: connected: expr=127.0.0.1:60574
2011-05-29T00:50:24: [INFO]: (127.0.0.1:60574): GET /c.kcd/59/47/04b09ad074b6c9c58132c3dbfd81879f6294efbe9f1381ae295cf2ac HTTP/1.1: 200
2011-05-29T00:50:24: [INFO]: connected: expr=127.0.0.1:60575
2011-05-29T00:50:24: [INFO]: (127.0.0.1:60575): PUT /a.kcd/59/47/04b09ad074b6c9c58132c3dbfd81879f6294efbe9f1381ae295cf2ac HTTP/1.1: 201
2011-05-29T00:50:37: [INFO]: connected: expr=127.0.0.1:60766
と想定通りのアクセスがきています。まず、murmurhashを使ったsort順に、c.kcd(3)、b.kcd(2)にPUTし、キューに回し、キューは c.kcd(3) からオブジェクトを一旦取得し、a.kcd(1) にPUTしてレプリカを作成します。
と、GreenBucketsでKyoto Tycoonが利用できることが確認できました。もちろんKyoto Cabinetがサポートする他のデータベースでも問題なく使えますし、揮発性のある分散Object Storageも作れます^^。画像ストレージとして考えた場合、Directory Hash Database を選ぶことになると思うのですが、ファイルがすべて1つのディレクトリに保存されてしまうので、lsが遅いとか扱いにくいのがアレかもしれません。
合わせて読みたい