弊社では毎週水曜日はノーエンジニアデーなので、最近はMacbook AirとWIMAX持って外で仕事しています。意外と快適ですが、ここで書くのはサーバの使い方の話です。
ときおり、次のような状況に遭遇することがあります。
- 開発環境して使っているけど、セットアップをどのように行ったか残っていないので、新サーバへ移動できない
- 本番環境だけど、セットアップをどのように行ったかわ(ry
- デプロイ元/管理ツールサーバとして使っているので古いサーバだけど捨てることができない
- DBがどこから参照されているか管理できていないので、サーバの入れ替えが困難
- コードがどこから参照が把握できていないので、容易にサーバ構成の変更ができない
椅子^H^H
一度設置したサーバの移動なんてなかなかすることないと思う人はいるかもしれないけど、サーバが何の警告もなしに突然壊れて入れ替える必要がでてくるのはもちろん、インフラ技術が進歩している今、古い環境を残し続けるより電力あたりの性能がいいサーバに入れ替えをしたり、スケーラビリティを求めてデータセンターからクラウドへ移行、クラウドから別のクラウドへの引っ越し、クラウドからデータセンターへ移動しながら、インフラを積極的に最適化を行って行くのが当たり前になっている(なっていくと思う)
個人の開発環境でもより快適な、効率の良い環境を求めて、デスクトップ、ラップトップ、サーバ、クラウドとWorkdirを移動するよね。
サービスの最適化を積極的に行っていくためにも、Webアプリケーションの実行環境、開発環境もいつでも引っ越しができるように、移動がしやすいようにしておきたいものです。そのために以下のような点を気にしてもらえるといいと思います
dotfilesをVCSを使って管理する
エンジニアは自分の環境をカスタマイズする人間ですが、カスタマイズの内容をすべて覚えていたりはしないでしょう。シェルやエディタの設定ファイルはすべてVCSを使って管理していくのがお勧めです。また、本番環境は複数人のエンジニアが触る可能性があるので、カスタマイズを行わなくても最低限の作業ができるようして置きましょう。
実行可能な形式でセットアップのメモを作る
サーバの設定をドキュメントで残すことは必ず行われると信じてますが、意味のあるドキュメントとするためにも、ドキュメント自体をシェルスクリプトにしたり、コピペで実行できるものにしておきたいものです。ドキュメントに『「Foo」と「Bar」をインストールする』と書かれるより、
$ sudo yum -y install Foo Bar
と書いてあれば、そのまま実行でき、ドキュメントの維持のモチベーションにも繋がります
大規模サーバ環境ではPuppetやChefなどを使って構成管理したり再利用可能なフレームワークを利用しますが、それはそれ。小規模なものであれば、設定をシェルスクリプトにして、sshでリモート実行という手でも自動化は十分なはずです。もちろん、作成したメモはVCSやwikiで管理しましょう。Word?Excel?何それおいしいの?
自動化の際に一つ難しいのが、設定ファイルの一部だけを書き換えるという処理です。sedやperlを使って部分的に書き換えるのも手ですが、設定ファイル自体をVCSで管理して、設定スクリプトにてsymlinkを張ってしまうのも方法もありです。
シェルスクリプトにする際のコツですが、
CURRENT=$(cd $(dirname $0) && pwd)
とすると、スクリプトがあるディレクトリがとれるので。シェルスクリプトと設定ファイルを同じディレクトリにおいて
mv /etc/init.d/httpd.conf /etc/init.d/httpd.conf.bak
ln -s $CURRENT/httpd.conf /etc/init.d/httpd.conf
と簡単に書くことができます。絶対パスへの依存は極力なくしていくことが大事
同じスクリプトを繰り返し実行しても問題ないように
if [ ! -L /etc/init.d/httpd.conf ]; then
mv /etc/init.d/httpd.conf /etc/init.d/httpd.conf.bak
ln -s $CURRENT/httpd.conf /etc/init.d/httpd.conf
fi
としておくと安全ですね
サービス間の連携は疎結合で
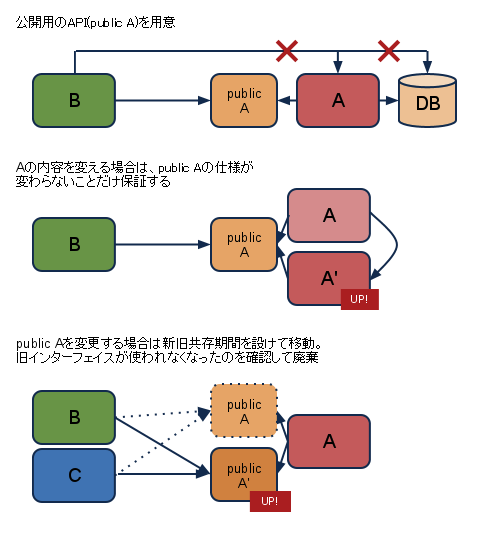
異なるサービスを連携させる際には、互いの関係を疎に保ちましょう。ルールのないコード参照/データベースへの接続はダメゼッタイ!
もしAというサービスがBというサービスから使われる場合、Aに公開用のインターフェイスを設け、Bはそれを利用します。Aを構成変更する場合インターフェイスがこれまで通り動作することだけを保証すればよくなるので問題が減ります。もしインターフェイスの仕様を変更したい場合は、新旧両方のインターフェイスを稼働させ、Bからの(もしかするとCもDも)古いインターフェイスへの接続がなくなったことを確認して、閉じると問題なく仕様変更が可能となります
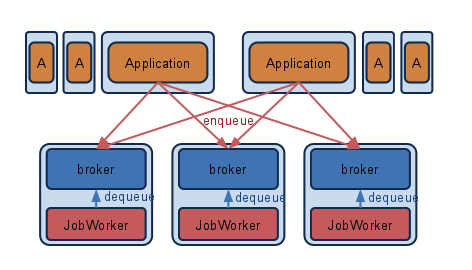
長時間かかる処理は小さい単位にjobを分割して実行する
実行に数時間かかるようなバッチがある場合、そのバッチが動いている最中はサーバをいじることができません。もしその間に障害があったとして、復旧後に処理を最初からやり直すとするとまた数時間処理が続くことになります。大変ですね
長時間かかるバッチは、処理をretryが可能な小さい単位に分割し、JobQueueを使って全体をつなげるとリスクを減らすことができます。
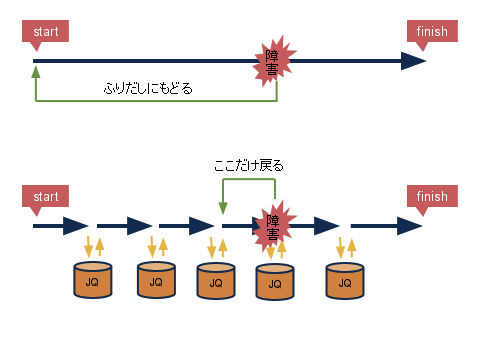
長時間に渡るバッチやデーモンプロセスでは安全にプロセスを停止でき、不整合なく処理を再開できるようにしたいものです。
オペレーションエンジニアに相談する
サーバの使い方で困ったらオペレーションエンジニアに相談しましょう。彼らの経験を元にアーキテクチャを考えたり、セットアップの自動化やサーバ移転作業などいろいろ手伝ってくれるはずです!