Monoceros というPSGI/Plackサーバ書きました
https://metacpan.org/release/Monoceros
https://github.com/kazeburo/Monoceros
StarmanやStarletのようなPreforkなアプリケーションサーバでは、コネクションの維持イコールプロセスの占有なので、HTTPのKeepAliveは無効にするのが一般的ですが、負荷の高いサービスではTIME_WAIT状態のソケットが溜まったり、SYN-ACKの再送問題などあり、KeepAliveを使いたいという欲求があったりなかったりします。
Monoceros
はリクエストを処理するworkerの他に、イベントドリブンで動くコネクション管理プロセスを立てて、クライアントからの接続ソケットをunix domain
socketを使いプロセス間でやりとりします。待機中の接続をPreforkなworkerではなくイベントドリブンのプロセスで管理することで、プロセスを占有することなく大量のコネクションを捌く事ができます。適切に設定すれば10000接続もいけると思います。
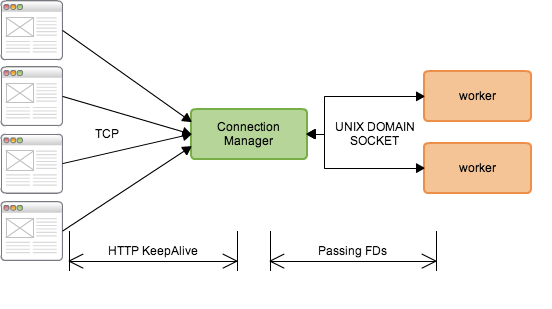
コネクション管理プロセスではAnyEventを使って接続をイベントドリブンで処理して、クライアントからの接続ののち最初のリクエストが読み取れる段階になったらIO::FDPassを使ってWorkerにソケットを受け渡します。Workerは受け取ったソケットからリクエストを読み取ってクライアントにレスポンスを直接返します。KeepAliveが有効であれば、その接続を維持して再度読み込み待ちにするようにコネクション管理プロセスに情報を送信し、Workerは次のリクエストに備えます。
実際にはDEFER_ACCEPTの処理やmax_keepalive_requestに達した際の処理があるのでもう少し複雑です。興味のある方はソースコードを参考にしてもらえたらと思います。
Workerは、高速で安定しているStarletを継承してほぼそのまま利用しています。なので現状HTTP/1.0のKeepAliveだけをサポートしています。
ベンチマーク
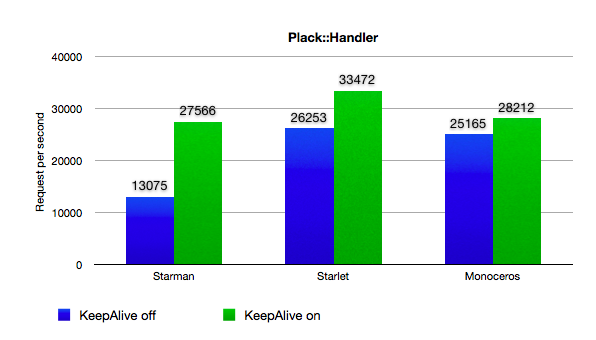
さっそくベンチマークです。MonocerosとStarman/Starletを比べてみます。
今回ベンチマークに使った各ソフトウェアのバージョンは以下になります
Plack (1.0023)
EV (4.15)
Guard (1.022)
Starlet (0.18)
HTTP::Parser::XS (0.16)
Monoceros (0.08)
Starman (0.3011)
サーバは Xeon L5630 2.13GHz 4コア/8スレッド を2つ積んだサーバです
それぞれ以下のオプションで起動します。MonocerosとStarmanは1接続あたりのKeepAliveリクエスト数の上限設定がありません。
$ carton exec -- plackup -E production --port 5000 --max-workers=15 -s Starlet --max-keepalive-reqs=50000 --max-reqs-per-child=50000 -a app.psgi
$ carton exec -- plackup -E production --port 5000 --max-workers=15 -s Monoceros --max-reqs-per-child=50000 -a app.psgi
$ carton exec -- starman --preload-app --workers=15 --max-requests=50000 -a app.psgi
app.psgiの中身は
use Plack::Builder;
my $length = 12;
my $body = 'x'x$length;
builder {
enable 'AccessLog', logger => sub { };
sub {
#select undef,undef,undef,0.01;
my $env = shift;
my $req = Plack::Request->new($env);
my @params = $req->param('foo');
[200, ['Content-Type'=>'text/plain','Content-Length'=>length($body)],[$body]]
}
};
になっています。
ベンチマークに使った ab のオプションは
KeepAlive無効時 $ ab -c 100 -n 50110 http://../foo?foo=bar&bar=baz&baz=hoge&hoge=foo
KeepAlive有効時 $ ab -k -c 100 -n 50110 http://../foo?foo=bar&bar=baz&baz=hoge&hoge=foo
ベンチマーク結果
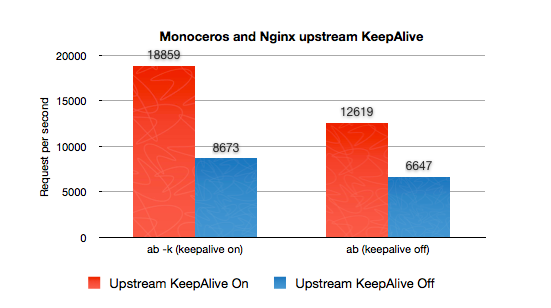
まず、MonocerosはKeepAlive無効時にStarletとほぼ同等の性能がでます。内部の動作でもselect(2)が一回多いだけでほぼ同じ動きをしています。
そしてKeepAliveを有効にした場合、StarmanとStarletが大きく数値を伸ばしているのに対して、Monocerosは少し増えただけのように思えます。
これにはいくつか理由があります。まずabは接続できたコネクションを優先して使ってリクエストを行います。-c
100と同時接続数を100に指定しても実際には100回の接続を均等に使いません。最初に接続できたコネクションを中心にリクエストを行ってしまいます。Starman/Starletでは
—workers/—max-workers に指定された値、ここでは15接続に偏ってアクセスします。
Starman/Starletでは1つの接続が1つのプロセスを占有して処理されるのでKeepAlive有効時に高速になりますが、逆にMonocerosではAnyEventのプロセスとworker間のソケットのやりとりをして多くの接続を受け付け、接続とプロセスを分離して扱えるように設計されているので、その分多少のオーバーヘッドがあります。それでもKeepAlive有効時に高速になるようにkazuho氏のアドバイスの参考に様々な工夫をしています。
Monoceros雑感
http://d.hatena.ne.jp/kazuhooku/20130425/1366851011
kazuho++
KeepAlive Timeoutを考慮したベンチマーク
ApacheBenchの動作は上で説明した通りなのですが、実際のブラウザ/Proxyとの通信では状況が異なります。KeepAliveを使って何回かのリクエストを行った後もまたその接続を使い回す可能性あるので、ブラウザ側かサーバ側でコネクションを切断するまで何もしない状態で接続が維持されます。Starman/Starletではそういった接続でも1つのプロセスを占有してしまうので、次のリクエストを受け付けることができなくなります。
Starman/Starletにある —keepalive-timeout
というオプションはKeepAliveの次のアクセスを待つまでの時間で、通信のない接続にプロセスがいつまでも占有されてしまうのを防ぎます。ApacheではKeepAliveTimeoutですね。
以下のブログも参考になります。
keep-aliveでHTTPコネクションを放置するベンチマーク(abパッチ)
http://mtl.recruit.co.jp/blog/2008/09/keepalivehttpab.html
上記のブログと同じようなベンチマークをperlのCoroとFurlを使って書いてみました。FurlはデフォルトでKeepAliveになります。
use strict;
use warnings;
use 5.10.0;
use AnyEvent;
use Coro;
use FurlX::Coro::HTTP;
use Time::HiRes;
use Statistics::Basic qw(:all);
use List::Util qw/max min/;
my $reqs_per_thread = $ARGV[0];
my $threads = $ARGV[1];
my $url = $ARGV[2];
my $cv = AE::cv;
my @coros;
my @statistics;
my $errors = 0;
my %ua;
for my $id (1..$threads) {
$cv->begin;
push @coros, async {
warn "[$id] start";
$ua{$id} = FurlX::Coro::HTTP->new(
timeout => 5,
);
for (1..$reqs_per_thread) {
my @t = Time::HiRes::gettimeofday;
my @res = $ua{$id}->get($url);
my $ela = Time::HiRes::tv_interval ( \@t );
push @statistics, $ela;
$errors++ if $res[1] != 200;
}
warn "[$id] end";
$cv->end;
};
}
my @t = Time::HiRes::gettimeofday;
$_->join for @coros;
$cv->recv;
my $total = Time::HiRes::tv_interval ( \@t );
say sprintf 'finished in %s sec. concurrency: %s reqs_per_thread: %s', $total, $threads, $reqs_per_thread;
say sprintf 'requests: failed %s', $errors;
say '= per-reqs statistics =';
say sprintf 'minimum: %s sec', min(@statistics);
say sprintf 'maximum: %s sec', max(@statistics);
say sprintf 'average: %s sec', average(@statistics);
say sprintf 'median: %s sec', median(@statistics);
1接続に付き250リクエストを接続数100と1000でStarletとMonocerosに対して実行してみます
まずStarlet。
■接続数100
finished in 15.043832 sec. concurrency: 100 reqs_per_thread: 250
requests: failed 80
= per-reqs statistics =
minimum: 0.000444 sec
maximum: 5.991323 sec
average: 0.03 sec
median: 0 sec
■接続数1000
finished in 177.534857 sec. concurrency: 1000 reqs_per_thread: 250
requests: failed 14765
= per-reqs statistics =
minimum: 0.00041 sec
maximum: 6.146582 sec
average: 0.37 sec
median: 0 sec
5秒以上リクエスト(接続)に時間が掛かかることもあり、何度もリクエストに失敗しています。
次にMonoceros。
■接続数100
finished in 4.0479 sec. concurrency: 100 reqs_per_thread: 250
requests: failed 0
= per-reqs statistics =
minimum: 0.000625 sec
maximum: 0.045615 sec
average: 0.02 sec
median: 0.02 sec
■接続数1000
finished in 43.784275 sec. concurrency: 1000 reqs_per_thread: 250
requests: failed 0
= per-reqs statistics =
minimum: 0.001168 sec
maximum: 0.402207 sec
average: 0.17 sec
median: 0.17 sec
全体の掛かる時間が短くなりました。リクエスト単位でも最大で0.4秒でレスポンスが得られ、リクエストが失敗するとはありません。Starletに比べて最短のレスポンス時間とレスポンス時間の中央値が悪くなっていますが、このあたりがMonocerosのオーバーヘッドなのでしょう。
結論
アプリケーションサーバでKeepAliveを有効にして大量の接続を維持し隊!ということがあればMonocerosは十分に使えると思われます。ぜひお試しください