去年の第一回では、次の日に3時間の昼寝をしていたようですが、今年は開催中に体調を崩してしまい、参加者の皆様がハックをしている最中にクッションで横になっているという状態になってしました。セットアップの不手際と合わせて申し訳ないと思っています。また家の事情的なこともあり、準備段階であまり協力できなかった中、ibuchoさん、941さん、やぶたさん、tagomoris、sugyanには感謝しております。そして参加者、協力して下さった方みなさまに感謝しております
livedoor
Techブログ : #isucon2 リアルタイムフォトレポート 更新終了
livedoor
Techブログ : #isucon2 参加者・関連エントリまとめ
tagomoris/isucon2 - GitHub
ISUCON2では課題となったチケット販売サイトのアプリケーションの作成はsugyanが行い、ベンチマークツールはtagomorisが構築しています。お前は何をやっていたのかというと、PRE-ISUCON(自称)として課題アプリケーションの高速化に取り組んで、実際にどの程度まで数字がでるのか、またベンチマークツールやチェックスクリプトに抜けはないかなどなどのために日夜ごにょごにょしておりました。なによりこの期間にやっていたことをtwitterにつぶやけなかったのが厳しかったです^^
その結果として出したのが以下の数字。
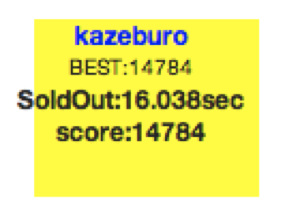
優勝のfujiwara組(二連覇おめでとうございます!本当にすごい!)が83474なので、約5.6倍のスコアとなっています。7時間で達成したfujiwara組と異なり、この数字を出すまでに一週間程度掛けているので単純比較できるものではない点はご注意ください。
ベンチマークツールについて
さて、今回のISUCONのベンチマークツールの構成は1+3のツールに分かれています。
- (1) データの初期化と数枚のチケット購入を行い、1秒後にチケット購入の順序確認とサイドバーの更新の確認を行う starter.js
- (2) トップページからページをたどり、最終的にチケットを購入する buyer.js
- (3) 各静的コンテンツのMD5値の確認と、チケット購入を行い、1秒後に座席表の更新を確認する checker.js
- (4) http_load + patchで負荷を掛ける httpload.js
(1) のstarter.js
が正常に終了したのを確認したあと、(2)から(4)が同時に起動します。buyerは25並列のプロセスが4つ、checkerは1並列1プロセス、httploadは50並列2プロセス、合計201並列でアプリケーションに対してリクエストを行います。
最終的なスコアは、この4プロセスのうち、(2)と(4)で決まります。
スコア = X - (Y * 0.01 + Z * 0.001)
X. チケット購入の完売までの所要時間(ms)
Y. 完売後の購入リクエスト処理数
Z. 全体でのGETリクエスト処理数
X.
のほとんどは(2)のbuyer.jsによるリクエスト、Zは(4)のhttp_loadによるリクエストになりますが、Zは1/1000されることから実質的にはチケット完売までの所用時間によって勝負が決まるようになっていました。
ここから僕のハックの話
静的ファイルへの書き出し
sugyanのアプリケーションを見た際に、まず最初に考えたのがたぶん多くのチーム同様最新n件を取得するクエリの改良です。しかしこれはいくつか試したあとすぐに諦めました。それよりも全体のHTMLを1秒以内に静的に書き出してしまう方が、圧倒的に高速だからです。今回のアプリケーションでは
- トップページ
- アーティストごとのページ * 2
- 座席表ページ * 5
の合わせて9ページのみなので、全てを事前にファイルに書き出し、また購入後1秒以内にすべて更新しなおすことができれば表示時の負荷はなくなります。人の1秒は刹那でもコンピュータの1秒はかなりいろいろなことができます。この手法は数分でグッズを売り切るLINEシークレットセールでも使っています。
このHTML書き出しのスクリプトがこちら
事前gzip
次に取り組んだのが、コンテンツの圧縮です。今回のISUCONのコンテンツはどれもサイズが大きくなっているのでgzip圧縮が必須です。(なのでベンチマークツールにもAccept-Encodingヘッダをいれてます)
- チケットページ - 300KB
- jquery - 91KB
- jquery-uri.js - 200KB
- jquery-ui.css - 33KB
- isucon_title.jpg - 31KB
これらのページを配信時にgzip圧縮していたのではCPUに負荷が掛かりすぎてしまいます。そこで事前にgzip圧縮を掛けて、WebサーバでリクエストのAccept-Encodingをみて、配信仕分ける方法とりました。nginxでは、HttpGzipStaticModuleを使います。HttpGzipStaticModuleは標準ではインストールされないので、configureで指定が必要です
./configure --with-http_gzip_static_module
設定では
gzip_static on;
とするだけです。
query-uri.js
query-uri.js.gz
と2つのファイルがあればAccept-Econdingにそって出し分けできます。これを使いjsやcssはすべて圧縮し、トップページなどもHTMLを書き出す際にgzip圧縮版も用意して配信時の負荷を削減しました
トランザクションレス => RDBMSレス
最期に残ったのが購入リクエストの処理です。元の購入トランザクションはわざとらしく複雑に書かれています
$dbh->begin_work;
$dbh->query('INSERT INTO order_request (member_id) VALUES (?)',$member_id);
my $order_id = $dbh->last_insert_id;
my $rows = $dbh->query(
'UPDATE stock SET order_id = ? WHERE variation_id = ? AND order_id IS NULL ORDER BY RAND() LIMIT 1',
$order_id, $variation_id,
);
if ($rows > 0) {
my $seat_id = $dbh->select_one(
'SELECT seat_id FROM stock WHERE order_id = ? LIMIT 1',
$order_id,
);
$dbh->commit;
render('complete.tx', { seat_id => $seat_id, member_id => $member_id });
} else {
$dbh->rollback;
}
くせ者は「order_id」と席の順をランダムに決定する「ORDER BY
RAND()」の2つです。後者についてはstarterでのチェック漏れがあったようですが。。
今回のベンチマークの中では「order_id」はシーケンシャルな番号が求められていないので、ユニークな番号があればそれで代替できます。そして席のランダム性はデータを作る段階でランダムな順を決めてしまえば購入時に選ぶ必要ありません。そこで以下のように席の種類ごとに1からその個数までのランダムな番号を振っていきました。
my $variations = $dbh->select_all(
'SELECT id, name FROM variation ORDER BY id',
);
for my $variation (@$variations) {
my $stock_count = $dbh->select_one('SELECT COUNT(*) FROM stock WHERE variation_id = ?',$variation->{id});
my @rid = shuffle( 1..$stock_count );
my $rows = $dbh->select_all('SELECT id FROM stock WHERE variation_id = ?', $variation->{id});
for my $row ( @$rows ) {
my $rid = shift @rid;
$rid = $variation->{id} * 100_000 + $rid;
$self->dbh->query('UPDATE stock SET rid = ? WHERE id=?',
$rid, $row->{id});
}
}
すると、購入は、席の種類ごとにシーケンシャルなIDが返せるミドルウェア(例えばmemcached)を導入し
my $max = $memcached->get('max_id:'.$variation_id);
my $rid = $memcached->incr('vari_id:'.$variation_id);
if ( $rid > $max ) {
return $c->render('soldout.tx');
}
$rid = $variation_id * 100_000 + $rid;
my $rows = $dbh->query('UPDATE stock SET order_id = ? WHERE rid=?',$rid,$rid);
と書けるようになります。さらに、incrされた事で購入されたことが自明になるので、最期のUPDATEクエリも削除し
my $max = $memcached->get('max_id:'.$variation_id);
my $rid = $memcached->incr('vari_id:'.$variation_id);
if ( $rid > $max ) {
return $c->render('soldout.tx');
}
$rid = $variation_id * 100_000 + $rid;
my $seat_id = $self->memcached->get('rid:'.$rid); #事前にcache
となりました。DBへの書き込みはHTMLに書き出すworkerで行えば1秒以内にDiskに書き込まれるのでまぁまぁ安心です。ここまでシンプルになればperlで実装する必要もなくなり、lua-nginx-moduleを使ってnginx上だけで購入までできるようにしました。それがこのXSS/SQL-injectionありまくりのソースコード。
今回はlua-nginx-moduleやmemcached、mysqlへのアクセスを行うためこれらのパッケージがバンドルされているopenrestyを使いました
トラフィック対策
ここまできてのスコアは25000程度で、たまにFailする状態でした。かなり悩んで気付いたのが通信量で、トラフィック多すぎて購入リクエストが邪魔されたり、通信にCPUがとられHTML書き出しが遅くなっているんじゃないかということが分かりました。そこで、思い切ってhttp_load対策としてnginxに
location ~ ^/(images|js|css)/ {
rewrite_by_lua 'ngx.sleep(2.5)';
root ../../../staticfiles;
}
として、静的ファイルの配信にdelayをいれてみました。スコア算出でhttp_loadの割合が低い事、また購入buyer.jsではこれらのファイルにアクセスしないのでできた技です。
これでめでたく最終的なスコア「14787」となりました
さいごに
僕のコードはすべてgithubにて公開されています。
https://github.com/kazeburo/isucon2_hack/
ぜひみて頂ければと思います。
これからの楽しみ方としては、starter.jsやchecker.jsにさらに厳密なチェック、例えばorder_idがシーケンシャルになっていることや、サイドバーの出現順序の確認が加わったらどう実装するか、またbuyerでjsにアクセスしたら?などを考えるとあなたのマゾ度が試されて面白いかもしれません。
