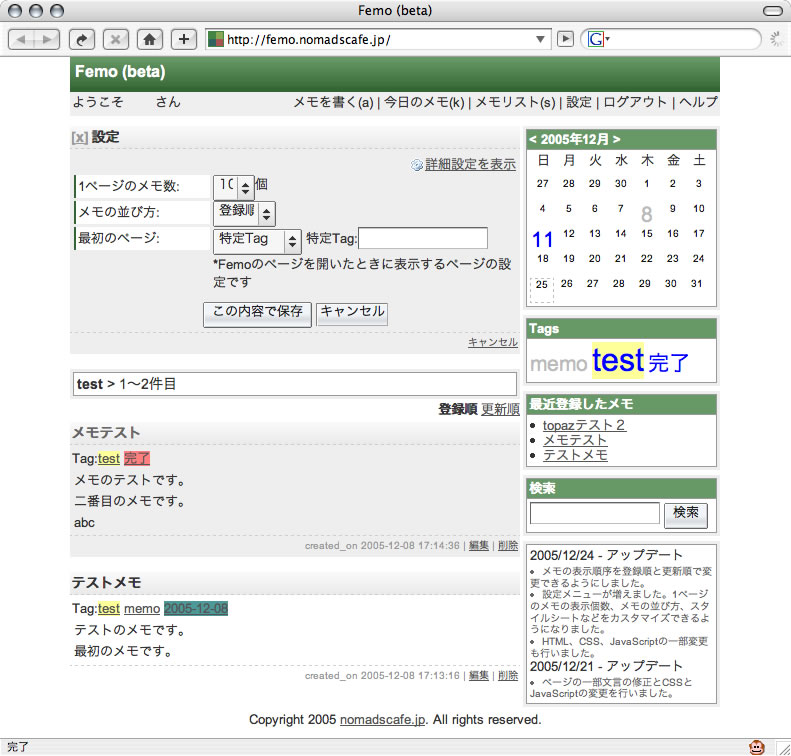
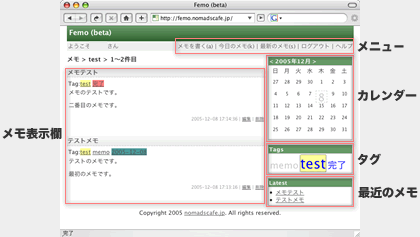
prototype.jsのものすごく簡単な使い方。
はてなダイアリーの方にprototype.jsでHTMLを汚さないロールオーバースクリプトというエントリーを書いたのだが、prototype.jsの入手方法やらすごく簡単な使い方がないようなので、書いてみます。
prototype.jsはJavaScriptのライブラリ(中身はJavaScriptです)で、これを使うとJavaScriptを組むのがかなり楽になるというものです。話題のAjaxのプログラミングも簡単にできます。
ライブラリは、
http://prototype.conio.net/
からダウンロードできますが、TOPページにあるファイルはちょっと古いものなので、Browse the darcs repositoryというリンクを辿り、。
http://dev.conio.net/repos/prototype/dist/
からprototype.jsをダウンロードします。右クリックで「リンク先を保存」でOKです
1.4.0がでているので、「Download the latest version」というリンクからファイルをダウンロード&解凍します。prototype.jsは、distディレクトリ下にあります。
prototype.jsを使うには、HTMLからリンクするだけでOKです。scriptタグのsrc属性を使います。headの中などで、
<script type="text/javascript" src="prototype.js"></script>
と書くだけです。
この場合は、HTMLファイルとprototype.jsは同じディレクトリに置くことになります。もちろん違うディレクトリでも大丈夫です。
これで準備が整いました。さっそくすごく簡単なAjaxを作ってみましょう。
「ボタンをクリックしたら、Ajaxで別のファイルの内容を取りにいって、HTMLの一部をそれに置き換える」
というものを作ります。
下のようなHTMLを書きます。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>sample</title>
<script src="prototype.js" type="text/javascript"></script>
</head>
<body>
<p id="blk">ここがターゲット</p>
<input type="button" value="ボタン" onclick="new Ajax.Updater('blk','mess.html',{method: 'get'});"/>
</body>
</html>
これを「test.html」などとして保存します。もう一つ「mess.html」というファイルをつくり、
Ajaaaaaaaaaaaaaaaaaaaaaaaaaaaaax!!
とでも書いておきます。これは読み込まれる方のファイルです。両方のファイルともに漢字コードUTF-8にしておいてください。あと、先ほどのprototype.jsを同じディレクトリにいれます。
これで完成です。test.htmlを開いて、ボタンをクリックしてみるとテキストの内容が変化するハズです。
「mess.html」にimgタグを書けばきちんとその画像もでてきますよ。
Ajaxのほとんどの処理は、ボタンのonclickにつけられた
new Ajax.Updater('blk','mess.html',{method: 'get'});
これがやってます。Ajax.Updaterは「Ajaxで別のURLの内容を取りにいって、指定されたHTMLの部分をそれに置き換える」という機能です。
3つのパラメータを渡します。
1つ目は書き換えるHTMLエレメントのIDです。ここでは「id="blk"」が指定されているpタグの部分になります。
2つ目は内容を取得するURL
3つ目はオプションで、ここではGETメソッドを利用することを指定してます
prototype.jsにはこれ以外にも便利な機能がいくつかあります。詳しくは、
prototype.js
v1.3.1 の使い方
はてなの9月29日の技術勉強会
id:naoyaさんのppt資料
prototype.jsと PerlでAjax
などが参考になります。